- 작성일
- 2025.10.14
- 수정일
- 2025.10.14
- 작성자
- 김가랑
- 조회수
- 36
엔비디아, 강화 학습을 사전 훈련에 통합하는 새 방식 공개
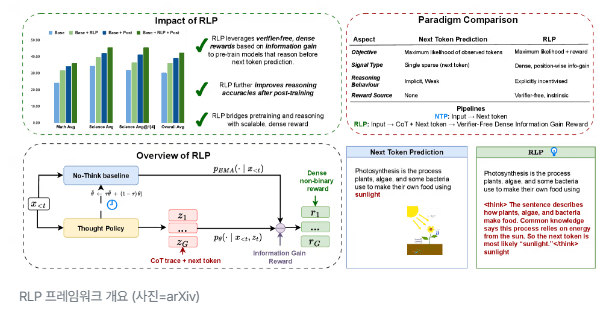
RLP 프레임워크 개요 (사진=arXiv)
엔비디아가 대형언어모델(LLM)의 학습 방식을 근본적으로 바꿀 새로운 접근법을 제시했다. 기존처럼 단어 예측 중심으로 학습하는 대신, 모델이 예측 전에 먼저 생각하도록 만드는 구조를 도입한 것이다.
엔비디아는 9일(현지시간) 기존처럼 모든 데이터를 단순히 ‘다음 단어 예측’으로 학습하는 대신 강화 학습(RL)을 사전 훈련 단계에 통합하는 학습 프레임워크 ‘RLP(Reinforcement Learning Pre-training)’을 온라인 아카이브를 통해 공개했다.
현재 대부분의 LLM은 방대한 텍스트를 기반으로 다음에 올 단어를 예측하는 과정을 반복하며 언어 패턴과 사실 관계를 학습한다. 이후 감독 학습(SFT)이나 인간 피드백 기반 강화학습(RLHF) 등을 통해 복잡한 추론(CoT) 능력을 추가로 익힌다.
하지만 엔비디아 연구진은 이런 순차적 학습 구조가 인간의 사고방식과는 다르다고 지적했다. 연구진은 “인간의 이해는 단어를 차례로 예측하는 것이 아니라, 입력 정보를 과거 지식과 병렬적으로 통합하는 과정”이라고 설명했다. 기존 LLM은 이런 사고 통합이 부족해 깊은 추론 능력을 초기에 형성하지 못한다는 것이다.
따라서 RLP는 모델이 예측하기 전에 ‘스스로 생각’을 생성하도록 유도한다. 모델은 주어진 문맥(context)을 기반으로 내부에서 사고의 흐름을 만들어낸 뒤, 이를 바탕으로 다음 단어를 예측한다.
이때 RL의 보상 신호(reward)는 ‘생각’이 예측 정확도에 얼마나 부합하는지를 자동 계산해 부여된다. 즉, 모델의 정확한 예측을 성공한 사고만 긍정 보상을 받는 구조다.
이 방식은 외부 검증자나 인간 없이도 모델이 스스로 유용한 사고 패턴을 익히는 RL을 가능하게 만든다. 연구진은 “RLP는 모델이 다음 단어를 예측하기 전에 먼저 스스로 생각하도록 유도함으로써, 사전 훈련 단계에서부터 독립적인 사고 행위를 가르친다”라고 설명했다.
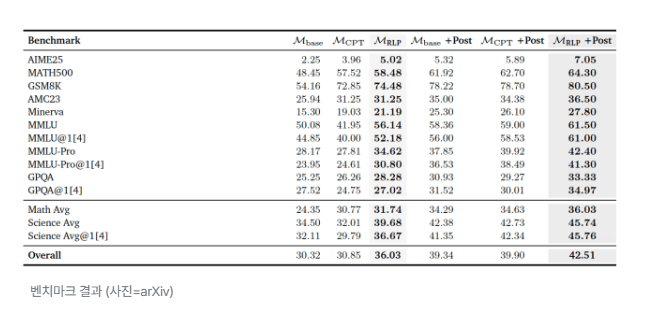
벤치마크 결과 (사진=arXiv)
엔비디아는 오픈 소스인 '큐원3-1.7B'와 '네모트론-나노-12B'에 RLP를 적용해 실험을 진행했다. 그 결과, 기존 방식으로 학습한 모델보다 수학·과학 분야의 복잡한 추론 과제에서 최대 23% 높은 정확도를 보였다.
큐원3-1.7B는 8개의 추론 벤치마크에서 평균 19% 점수가 상승했으며, 이후 동일한 후속 미세조정을 거친 경우에도 성능 향상 효과가 계속 누적돼 나타났다. 이는 일반적인 학습 과정에서 발생하는 '지식 망각'이 크게 줄어들었다는 것을 보여준다.
특히, RLP는 검증자 없는 밀집 보상 구조를 사용해 학습 효율성을 높였고, 기존보다 35배 적은 데이터로도 동일한 성능을 재현했다.
브라이언 카탄자로 엔비디아 연구 부문 부사장은 “RLP는 모델이 예측하기 전에 사고하도록 유도해, 더 일관된 논리 구조를 내재화하게 한다”라며 “복잡한 워크플로우에서 발생하는 미묘한 논리 오류를 줄이는 데도 도움이 될 것”이라고 설명했다
또 “RLP는 RLHF나 SFT흫 대체하기 위한 것이 아니라, 이후 학습 단계를 더 효과적으로 만드는 기반 기술”이라며, 추가로 사후 훈련하는 것이 여전히 필요하다고 덧붙였다.
박찬 기자 cpark@aitimes.com
- 첨부파일
- 첨부파일이(가) 없습니다.