- 작성일
- 2025.10.21
- 수정일
- 2025.10.21
- 작성자
- 김가랑
- 조회수
- 86
강화 학습 결과 예측 가능케 하는 LLM 법칙 공개
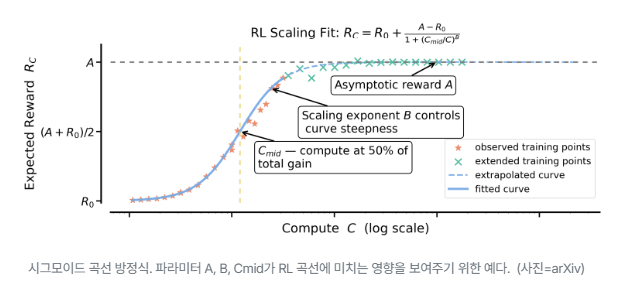
시그모이드 곡선 방정식. 파라미터 A, B, Cmid가 RL 곡선에 미치는 영향을 보여주기 위한 예다. (사진=arXiv)
대형언어모델(LLM)의 추론 능력을 강화하는 핵심 기술로 자리 잡은 강화 학습(RL) 에 처음으로 예측 가능한 확장 법칙이 제시됐다. 특히, 이번 연구에는 메타의 제안을 뿌리치고 스타트업에 합류한 유명 연구원이 참여했다.
메타와 텍사스대학교 오스틴, 유니버시티칼리지런던(UCL), 버클리대학교, 하버드대학교, 스타트업 피어리오딕 랩스 연구진은 17일(현지시간) 온라인 아카이브에 발표한 논문 'LLM을 위한 강화 학습 연산 확장의 기술(The Art of Scaling Reinforcement Learning Compute for LLMs)’을 발표했다.
이는 40만 GPU시간 이상을 투입한 대규모 실험을 통해 RL 성능을 수학적으로 예측할 수 있는 ‘컴퓨트-퍼포먼스 프레임워크’다.
기존 사전학습(pre-training)에서는 손실 감소와 연산량이 거듭제곱 법칙(power law)을 따르는 것으로 잘 알려졌지만, RL 학습은 정답률과 보상 등 목표 지표가 상한이 있는 특성 탓에 예측 모델이 없었다.
연구진은 이런 한계를 해결하기 위해 RL이 ‘시그모이드(Sigmoid) 곡선’을 따른다는 점을 밝혀냈다. 이 곡선은 학습 초반(약 1000~2000 GPU시간)에는 성능이 빠르게 오르지만, 이후에는 점점 향상 속도가 느려지는 형태다. 연구진은 이 시점 이후의 데이터를 이용하면 전체 학습 효율과 최고 성능을 예측할 수 있다고 설명했다.
이 결과를 토대로 ‘스케일RL(ScaleRL)’이라는 새로운 RL 방식을 제안했다. 이는 완전히 새로운 알고리즘이 아니라, 학습 효율을 높이고 안정적으로 규모를 확장할 수 있도록 설계된 구성 조합이다.
스케일RL은 오프-폴리시(off-policy) RL 방식을 바탕으로 ▲손실을 어떻게 합치는지(손실 집계 방식) ▲보상 값을 어떻게 정규화하는지(어드밴티지 정규화) ▲연산 정밀도를 어떻게 보정하는지(정밀도 보정) ▲데이터를 어떤 순서로 학습시키는지(데이터 커리큘럼) ▲배치를 어떻게 구성하는지(배치 정의) ▲어떤 손실 함수를 쓰는지(손실 유형) 등 여섯가지 알고리즘 요소를 추가로 분석했다.
오프-폴리시 RL은 데이터 수집 알고리즘과 학습 알고리즘이 다른 경우다. 예를 들어 직접 게임을 하며 게임 방법을 배우는 대신, 다른 사람의 게임 플레이를 구경하며 배우는 식이다.
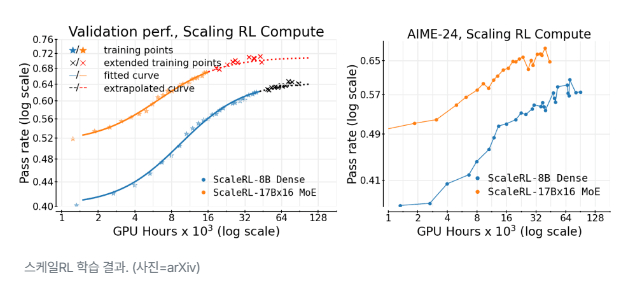
스케일RL 학습 결과. (사진=arXiv)
연구진은 스케일RL을 적용해 8000시간에서 1만6000시간, 나아가 10만 GPU시간으로 학습 규모를 확대한 실험을 진행했다.
그 결과, 예측한 시그모이드 곡선이 실제 성능 향상과 거의 완벽하게 일치한다는 것을 확인했다. 메타의 ‘라마-4 8B’와 ‘라마-4 17B×16 MoE(스카우트)’는 모두 이 예측 곡선을 그대로 따라갔으며, 'AIME-24' 등 다른 데이터셋을 사용한 벤치마크에서도 같은 결과가 나타났다.
이는 모델의 성능 향상이 단순한 데이터 과적합이 아니라, 실제 추론 능력의 개선이라는 점을 보여준다.
비교 실험 결과, 스케일RL은 '딥시크' '큐원-2.5' '매지스트랄(Magistral)' '미니맥스-M1' 등 기존 RL 레시피보다 더 높은 최대 성능과 우수한 연산 효율을 보였다.
연구진은 이런 차이를 분석, 학습 설계 요소를 두가지로 구분했다. 모델 크기나 출력 길이처럼 최종 성능의 상한을 높이는 요인(ceiling movers)과, 손실 계산 방식·정규화·데이터 커리큘럼처럼 학습 효율을 조절하는 요인(efficiency shapers)이다.
즉, 일부 요소는 모델이 도달할 수 있는 최고 성능을 끌어올리고, 다른 요소들은 그 성능에 도달하는 속도를 좌우한다는 것이다.
이번 연구는 RL 기반 LLM 학습을 체계적으로 분석하고, 그 과정을 예측 가능한 수준으로 끌어올렸다는 점에서 큰 의의가 있다.
연구진은 “이제 약 1000~2000 GPU시간만으로도 이후 수만시간의 학습 결과를 예측할 수 있다”라며 “무작정 컴퓨팅을 투입하던 기존 방식에서 벗어나, 데이터에 근거한 합리적인 RL 학습 설계가 가능해졌다”라고 강조했다.
한편, 이번 논문에 참여한 리샤브 아가르왈은 메타의 인재 영입을 뿌리치고 피어리오딕 랩스에 합류한 것으로 유명한 연구원이다.
이 회사는 오픈AI 출신 유명 연구자 리암 페두스 등이 설립한 'AI 과학자' 개발 스타트업으로, 지난달 3억달러(약 4200억원)의 시드 투자 유치로 화제가 됐다.
- 첨부파일
- 첨부파일이(가) 없습니다.