
인공지능(AI) 대형언어모델(LLM)이 문제 난이도에 따라 스스로 ‘생각하는 시간’을 조절하도록 만드는 새로운 추론 기법이 MIT 연구팀에 의해 공개됐다. 연구에 따르면 이 기법은 기존 방법보다 최대 절반의 계산량 감소로도 동일한 정확도를 달성하며, 작은 모델이 더 큰 모델을 능가하는 상황도 가능케 한다.
에너지 효율 개선은 물론 고난도·고위험 분야에서의 LLM 활용 가능성을 크게 확대할 수 있는 기술로 평가된다. MIT 기계공학과 및 데이터·시스템·사회연구소(Institute for Data, Systems, and Society, IDSS)의 나비드 아지잔(Navid Azizan) 교수 연구팀은 기존 LLM 추론 방식이 가진 한계를 지적한다. 일반적으로 ‘추론 시간 확장(inference-time scaling)’ 기법은 문제의 난이도와 관계없이 모든 질문에 동일한 계산 예산을 할당하는데, 이는 간단한 문제에 과도한 컴퓨팅을 낭비하고 복잡한 문제에는 오히려 계산이 부족해지는 비효율을 초래한다.
이번 MIT 연구팀이 제안한 방식은 ‘인스턴스 적응형 스케일링(instance-adaptive scaling)’이라는 새 프레임워크다. 핵심은 LLM이 문제를 풀어가는 과정에서 난이도와 성공 가능성을 실시간으로 판단하고, 그에 따라 계산량을 유연하게 조절한다는 점이다. 즉, “이 문제는 어렵지 않다”라고 판단하면 적은 계산으로 빠르게 답을 내고, “이 경로는 틀릴 확률이 높다”라고 판단하면 계산 경로를 줄이는 식으로 스스로 판단 능력을 강화한다.
“모델에게 ‘자기가 모르는 것을 아는 능력’을 준다”
아지잔 교수는 이번 연구가 GPT-5.1에서 강조된 ‘적응형 추론(adaptive reasoning)’의 핵심 원리를 실증한 것이라고 설명한다. 아지잔 교수는 “모델이 자기가 무엇을 모르는지 아는 능력을 갖게 하면, 어려운 문제에는 더 많은 계산을, 쉬운 문제에는 적은 계산을 쓰도록 설계할 수 있습니다. 이는 추론을 더 정확하게 만들고, 동시에 훨씬 효율적으로 만듭니다.”라고 말했다.
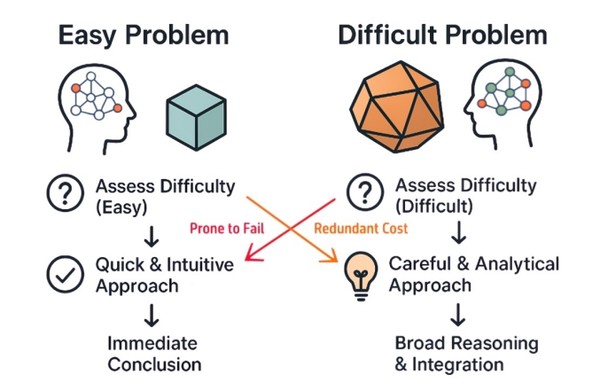
인스턴스 적응형 스케일링 방식은 프로세스 리워드 모델(Process Reward Model. 이하, PRM)을 활용한다. PRM은 모델이 만든 부분 답안, 중간 단계, 여러 경로의 ‘유망도’를 평가하는 보조 모델이다. 다만 기존 PRM은 종종 성공 확률을 과대평가하는 문제가 있었다.
제1저자인 박영진(Young-Jin Park) MIT의 정보·의사결정 연구소(LIDS, Laboratory for Information and Decision Systems) 및 MIT 기계공학과(MechE, Department of Mechanical Engineering) 대학원생은 “기존 PRM은 성공 확률을 심각하게 과대평가합니다. 그대로 사용하면 연산량을 지나치게 공격적으로 줄여버립니다"라며, "그래서 우리는 PRM을 더 정확히 보정해 추론의 효율성과 신뢰성을 동시에 확보할 방법을 찾는 데 집중했습니다.”라고 말했다.
연구팀은 PRM이 단일 확률값을 내놓는 대신 불확실성을 반영한 확률 분포를 출력하도록 보정했다. 이로써 모델은 자신이 확신할 수 없는 상황에서 무리하게 연산을 줄이지 않도록 균형을 맞출 수 있게 됐다.
MIT 연구팀은 이를 해결하기 위해 PRM을 단일 값이 아닌 ‘확률 범위’로 판단하도록 재설계했다. 이 방식은 불확실성을 보다 정확하게 반영해, 모델이 지나치게 계산을 줄이거나 불필요한 경로에 집착하는 문제를 방지한다.
“인간처럼 생각하는 LLM”...계산량 절반으로도 정확도 유지
연구팀은 수학적 추론 문제 세트를 통해 이 방식을 검증했다. 결과는 기존 추론 확장 기법보다 최대 50% 적은 계산량으로 동일한 정확도와 작은 모델이 더 큰 모델과 동등하거나 우수한 성능 달성, 문제 해결 과정에서 계산 분배를 실시간 조정하여 효율을 극대화시켰다.
크리스티안 그린월드(Kristjan Greenewald) MIT-IBM 왓슨 AI Lab 연구원은 “가장 큰 특징은 문제 해결 과정이 진행되는 동안 계산량을 조절한다는 것입니다. 사전에 모든 것을 결정하는 방식보다 훨씬 자연스럽고 효율적입니다.”라고 말했다.
고난도 의사결정 AI·코드 생성·AI 에이전트에 응용 가능
연구진은 향후 이 기술을 코드 생성 모델, AI 에이전트, 강화학습 시스템, 모델 자체 개선(continual self-improvement) 등으로 확장할 계획이다. IBM 소프트웨어 부문 코어AI 디렉터 아카시 스리바스타바(Akash Srivastava)는 “인간 직원은 일을 하면서 성장하지만, 지금의 AI 에이전트는 대부분 정적인 소프트웨어입니다"라며, "이 연구는 AI가 스스로 ‘이해하지 못한 것’을 인식하고 개선하는 기초 능력을 제공하는 중요한 출발점입니다.”라고 말했다. 그는 연구에 직접 참여하지는 않았지만 이 연구가 “자기 개선형 AI 에이전트 시대”로 가는 중요한 단계라고 평가한다.
LLM의 추론 비용이 폭증하고 있는 가운데, MIT가 제안한 방식은 AI 생태계 전반에 영향을 줄 잠재력을 가지고 있다. AI 서비스 운영 비용 절감, 데이터센터 전력 소비 감소 등으로 금융·물류·과학 연구·재난 대응 등 실시간 판단이 필요한 분야에서 활용도 증가할 것으로 기대된다.
한편, 이 연구는 MIT 기계공학과 및 데이터·시스템·사회연구소(IDSS) 소속의 나비드 아지잔(Navid Azizan) 교수가 주도했으며, 박영진 LIDS/MechE 대학원생 , MIT-IBM 왓슨 AI Lab의 크리스티안 그린월드(Kristjan Greenewald) 연구원, IDSS 대학원생 카베 알림(Kaveh Alim), 그리고 레드햇 AI 이노베이션 팀(Red Hat AI Innovation Team)의 하오 왕(Hao Wang) 등이 함께 참여했다.
이번 성과는 현지시간 지난 2일부터 7일까지 열린 인공지능 분야 최고 학회 중 하나인 신경정보처리시스템학회(NeurIPS 2025)에서 "모르는 것을 아는 것: 프로세스 보상 모델의 불확실성 보정(Know What You Don’t Know: Uncertainty Calibration of Process Reward Models-다운)'란 제목으로 발표됐으며, 관련 코드(다운)와 데이터셋(다운)은 현재 공개돼 있다.(아래는 박영진 대학원생의 소개 영상)
출처: https://www.aitimes.kr/news/articleView.html?idxno=37611