고급 추론 및 자율형 에이전트 워크플로우 최적화 설계... 파라미터당 전례 없는 수준의 지능 달성

구글은 역대 가장 지능적인 오픈소스 모델인 '젬마 4(Gemma 4)'를 2일(현지시간) 공개했다. 고급 추론과 에이전트 기반 워크플로우(Agentic workflows)를 위해 특수 설계된 젬마 4는 파라미터당
전례 없는 수준의 지능을 제공하는 것이 특징이다.
이러한 성과는 커뮤니티의 활발한 참여를 기반으로 이뤄졌다. 구글이 첫 번째 젬마 모델을 출시한 이후, 개발자들은 4억 회 이상 다운로드를 기록했으며, 10만 개 이상의 변형 모델로 구성된
‘젬마버스(Gemmaverse)’ 생태계를 구축해 왔다. 구글은 이를 반영해 AI 활용 가능성을 지속적으로 확장해 왔으며, 젬마 4는 이러한 흐름에 대한 결과물로 제시됐다.
젬마 4는 아파치 2.0(Apache 2.0) 라이선스로 제공되어, 상업적 활용을 포함한 폭넓은 사용이 가능하다.
제미나이 3와 동일한 세계 최고 수준의 연구 및 기술을 기반으로 개발된 젬마 4는 이용자의 하드웨어에서 실행할 수 있는 가장 강력한 성능의 모델 제품군이다. 젬마 4는 구글의 제미나이 모델을 보완하며,
개발자에게 개방형 모델과 폐쇄형 툴을 모두 아우르는, 업계에서 가장 강력한 조합을 제공한다.
업계 선도적인 역량 및 모바일 우선 AI 구글은 젬마 4는'이펙티브 2B(Effective 2B, E2B)', '이펙티브 4B(Effective 4B, E4B)', '26B 혼합 전문가(Mixture of Experts, MoE)' 및 '31B 덴스(Dense)' 모델 등
4종으로 전체 모델 제품군은 단순한 채팅을 넘어 복잡한 논리 처리와 에이전트 기반 워크플로우까지 지원한다.
모델들은 각 크기에서 최첨단 성능을 제공하며, 31B 모델은 현재 업계 표준인 아레나 AI 텍스트 리더보드(Arena AI text leaderboard)에서 오픈 모델 기준 3위, 26B 모델은 6위를 기록하고 있다.
또한 젬마 4는 20배 큰 모델들도 압도하는 성능을 보였다. 이처럼 향상된 파라미터당 성능은 개발자가 상대적으로 적은 하드웨어 자원으로도 높은 수준의 AI 기능을 달성할 수 있게 한다.
특히, 엣지 컴퓨팅 환경에서는 E2B와 E4B 모델이 온-디바이스(On-device) 활용성을 한층 확장했다. 이 모델들은 파라미터 수보다 멀티모달 기능, 낮은 레이턴시, 생태계와의 원활한 연동을 우선적으로
고려해 설계되었다.
강력하고 접근 가능한 개방형 모델구글은 차세대 혁신 연구와 제품 개발을 지원하기 위해 젬마 4를 다양한 하드웨어 환경에서 효율적으로 실행하고 미세 조정(fine-tuning)할 수 있도록 설계했다.
이 모델은 전 세계 수십억 대의 안드로이드 기기부터 노트북 GPU, 개발자 워크스테이션, 고성능 가속기에 이르기까지 폭넓은 환경에서 구동될 수 있다.
이처럼 고도로 최적화된 구조를 통해 개발자는 특정 작업에 맞춰 젬마 4를 미세 조정함으로써 최첨단 성능을 구현할 수 있다. 이미 이러한 접근 방식은 실제 사례로 이어지고 있다.
인세이트(INSAIT)는 불가리아어 중심 언어 모델 ‘비지피티(BgGPT)’를 개발했으며, 구글은 예일 대학교와 협력해 암 치료의 새로운 경로를 탐색하는 ‘셀투센텐스-스케일(Cell2Sentence-Scale)’ 프로젝트를
진행하고 있다.
젬마 4의 핵심 역량...“추론·에이전트·멀티모달까지 통합”
구글은 젬마 4를 자사 역대 가장 유능한 오픈 모델 제품군으로 규정하며, 그 핵심 경쟁력으로 다양한 고급 기능을 제시했다.
먼저 젬마 4는 다단계 계획 수립과 깊은 논리적 사고가 가능한 ▷'고급 추론 능력(Advanced Reasoning)'을 갖추고 있다. 이를 통해 수학 문제 해결이나 복합적인 지시 수행과 같은 고난도 작업에서
기존 대비 의미 있는 성능 향상을 입증했다.
또한 ▷'에이전트 기반 워크플로우(Agentic Workflows)'를 기본적으로 지원하는 점도 특징이다. 함수 호출(Function-calling), 구조화된 JSON 출력, 시스템 지침(System instructions)을 네이티브로
제공함으로써 다양한 툴과 API와 연동되는 자율형 에이전트를 안정적으로 구축할 수 있다.
▷'코드 생성 역량(Code Generation)' 역시 강화됐다. 젬마 4는 고성능 오프라인 코드 생성을 지원해 개발자의 워크스테이션을 로컬 중심(Local-first) AI 코드 어시스턴트로 전환할 수 있도록 돕는다.
멀티모달 기능도 포함됐다. 모든 모델은 ▷'이미지와 비디오(Vision and audio)'를 기본적으로 처리할 수 있으며, 가변 해상도를 지원한다. 특히 E2B와 E4B 모델은 음성 인식을 위한 네이티브 오디오
입력 기능까지 갖추고 있어 활용 범위를 더욱 확장했다.
▷'더 긴 컨텍스트(Longer context)' 처리 능력도 크게 향상됐다. 엣지 모델은 최대 128K, 대형 모델은 최대 256K의 컨텍스트 윈도우를 지원해 단일 프롬프트로도 긴 문서를 처리할 수 있다. 이와 함께
젬마 4는 140개 이상의 언어로 학습돼 글로벌 환경에서도 고성능 애플리케이션 구축이 가능하도록 설계됐다.
더붕어, 다양한 하드웨어 환경에 최적화된 다재다능한 모델로 구글은 젬마 4를 다양한 하드웨어 환경과 사용 사례에 맞춰 활용할 수 있도록 여러 크기의 모델 가중치(weights) 형태로 제공한다.
이를 통해 개발자와 기업은 특정 인프라 제약이나 목적에 따라 모델을 선택할 수 있으며, 클라우드부터 엣지 디바이스까지 필요한 환경 어디에서든 최첨단(frontier-class) 수준의 추론 성능을
구현할 수 있도록 지원한다.
26B·31B 모델...개인용 환경에서도 구현되는 프런티어급 지능
구글은 26B 및 31B 모델을 통해 개인용 컴퓨터 환경에서도 오프라인 기반의 프런티어급 AI 성능을 구현할 수 있도록 설계했다.
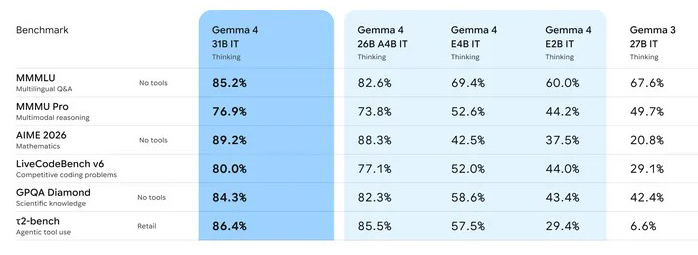
이들 모델은 연구자와 개발자가 접근 가능한 하드웨어에서 최첨단 추론 성능을 제공하도록 최적화됐으며, 비양자화(unquantized) bfloat16 가중치는 단일 엔비디아 H100 GPU에서도 효율적으로 실행된다.
또한 양자화 버전은 일반 소비자용 GPU에서도 구동 가능해 IDE, 코드 어시스턴트, 에이전트 기반 워크플로우 등 다양한 개발 환경을 지원한다.
특히 26B 혼합 전문가(MoE) 모델은 전체 파라미터 중 약 38억 개만 활성화하는 구조를 통해 레이턴시를 최소화하고 빠른 처리 속도를 제공한다. 반면 31B Dense 모델은 출력 품질을 극대화하는 데 초점을
맞춰 설계됐으며, 고성능 미세 조정을 위한 기반 모델로 활용할 수 있다.
E2B·E4B 모델…모바일·IoT 환경을 위한 초경량 AI
구글의 E2B 및 E4B 모델은 모바일과 IoT 기기를 위한 새로운 차원의 지능 구현을 목표로 설계됐다. 이들 모델은 연산 효율성과 메모리 사용을 극도로 최적화해, 추론 시 각각 약 20억(E2B), 40억(E4B)
규모의 파라미터만을 활용함으로써 메모리 점유율과 배터리 소모를 최소화한다.
특히, 구글 픽셀 팀을 비롯해 퀄컴, 미디어텍 등 주요 하드웨어 기업들과의 협력을 통해 스마트폰, 라즈베리 파이, 엔비디아 젯슨 나노와 같은 엣지 디바이스에서도 거의 제로에 가까운 레이턴시로 오프라인
실행이 가능하다.
또한 안드로이드 개발자는 AI코어 개발자 프리뷰(AICore Developer Preview)를 활용해 에이전트 기반 워크플로우를 사전에 구현할 수 있으며, 향후 제미나이 나노 4와의 호환성도 확보할 수 있다.
오픈소스 라이선스…개발자 주권과 생태계 확장
구글은 커뮤니티 중심의 협력적 AI 생태계 구축을 위해 젬마 4를 상업적 활용이 가능한 아파치 2.0(Apache 2.0) 라이선스로 제공한다. 이는 불필요한 제약 없이 개발자들이 자유롭게 모델을 활용하고
확장할 수 있도록 지원하겠다는 전략적 판단에 따른 것이다.
이 오픈소스 라이선스는 개발자에게 높은 수준의 유연성과 디지털 주권을 제공하며, 데이터와 모델에 대한 통제권을 확보할 수 있도록 한다. 이를 통해 기업과 연구기관은 자체 환경에 맞는 AI 시스템을
구축하고 운영할 수 있는 기반을 마련하게 된다.
이와 관련해 클레망 들랑주(Clément Delangue) 허깅 페이스 공동 창립자 겸 CEO는 “아파치 2.0 라이선스로 젬마 4를 출시한 것은 거대한 이정표”라며 “출시 첫날부터 구글의 젬마 4 제품군을 지원하게
되어 매우 기쁘다”고 밝혔다.
구글은 "젬마 4 모델에 자사 독점 AI 모델과 동일한 수준의 엄격한 인프라 보안 프로토콜을 적용해 신뢰성과 안정성을 확보했다."며, "이를 통해 기업과 개발자는 보안 및 신뢰성 측면에서 최고 수준의
기준을 충족하는 동시에, 최첨단 AI 기능을 활용할 수 있는 투명하고 검증된 기반을 확보할 수 있다"고 밝혔다.
한편, 구글은 젬마 4(Gemma 4) 출시와 동시에 개발자가 자신의 환경에 맞춰 즉시 모델을 도입하고 확장할 수 있는 폭넓은 생태계 지원 방안도 공개했다. 우선, 개발자는 구글 AI 스튜디오(보기)에서
31B 및 26B MoE 모델을, 구글 AI 엣지 갤러리에서 E4B 및 E2B 모델을 직접 테스트할 수 있다. 또한 안드로이드 개발자는 안드로이드 스튜디오(Android Studio-보기)의 에이전트 모드와 ML Kit GenAI
Prompt API(보기)를 활용해 프로덕션 환경까지 확장할 수 있다.
개발 환경의 유연성도 강조된다. 허깅 페이스, vLLM, 올라마, NVIDIA NIM 등 다양한 도구에서 출시 당일부터 지원이 제공되며, 모델은 현재 허깅페이스(Hugging Face-다운), 캐글(Kaggle-다운)
또는 올라마(Ollama-다운) 등에서다운로드할 수 있다.
또한 개발자는 구글 콜랩, 버텍스 AI, 개인용 게이밍 GPU 등 선호하는 환경에서 젬마 4를 직접 학습시키고 최적화할 수 있다. 로컬 온디바이스 추론은 오프라인 환경에 적합하며, 필요 시 구글 클라우드를
통해 서비스 확장이 가능하다. 이 과정에서 버텍스 AI, 클라우드 런(Cloud Run), GKE, 소버린 클라우드(Sovereign Cloud), TPU 가속 서빙 등 다양한 배포 옵션을 활용할 수 있으며, 규제 환경에서도 요구되는
높은 수준의 컴플라이언스를 충족할 수 있다.
하드웨어 측면에서도 폭넓은 지원이 제공된다. 엔비디아 젯슨 나노부터 블랙웰(Blackwell) GPU까지 엔비디아 AI 인프라에서 높은 성능을 제공하며, 오픈소스 ROCm™ 스택을 통해 AMD GPU와도 연동된다.
또한 구글 클라우드 TPU를 활용해 대규모 확장이 가능하다.
한편, 개발자 참여를 확대하기 위해 캐글에서는 ‘젬마 4 굿 챌린지(Gemma 4 Good Challenge-보기)’가 진행되며, 이를 통해 다양한 혁신적 활용 사례가 창출될 것으로 기대된다.
출처: https://www.aitimes.kr/news/articleView.html?idxno=39411