
인공지능(AI) 기술이 빠르게 발전하고 있지만, 여전히 풀기 어려운 숙제가 하나 있다. 바로 '환각(hallucination)' 현상이다. 이는 AI가 사실이 아닌 내용을 마치 진실인 것처럼 자신 있게 말하는 것을 뜻한다.
오픈AI(OpenAI)는 지난 4일(현지시간) 발표한 연구 논문을 통해 대형 언어 모델(LLM)의 고질적 문제인 ‘환각’의 구조적 원인과 해결 방안을 제시했다.
연구팀의 '언어 모델이 환각을 일으키는 이유Why Language Models Hallucinate-다운)'라는 논문에 따르면, 언어 모델의 학습 및 평가 구조가 ‘모른다’고 답하는 것보다 ‘추측’을 장려하기 때문에 환각이 발생한다. 기존 평가 방식은 정답을 맞히면 점수를 주고, 모른다고 답하면 0점을 부여한다. 따라서 모델은 불확실한 상황에서도 답을 추측하도록 학습된다는 것이다.
언어 모델은 방대한 텍스트 데이터를 기반으로 ‘다음 단어 예측(next-word prediction)’을 통해 학습된다. 맞춤법이나 문법처럼 규칙성이 있는 패턴은 잘 학습하지만, 무작위적이고 희귀한 정보(예: 개인의 생일)는 정확히 예측하기 어렵다. 이로 인해 특정 사실 오류가 발생하게 된다.
예컨대 어떤 인물의 생일을 묻는 질문에 모델이 “모른다”고 답하면 0점을 받지만, “9월 10일”이라고 추측하면 낮은 확률로나마 맞을 수 있다. 이러한 구조적 문제 때문에 모델은 정확성보다 ‘자신감 있는 추측’을 택하게 된다는 설명이다.
오픈AI는 환각을 줄이기 위해 평가 지표 개편이 필요하다고 강조했다. 단순히 정확성만 측정하는 대신, ‘확신에 찬 오답’에는 더 큰 감점을 주고 ‘모른다’는 겸손한 답변에는 부분 점수를 주는 방식이다. 이는 일부 표준화 시험에서 무작정 찍기를 막기 위해 오답에 감점을 주는 방식과 유사하다.
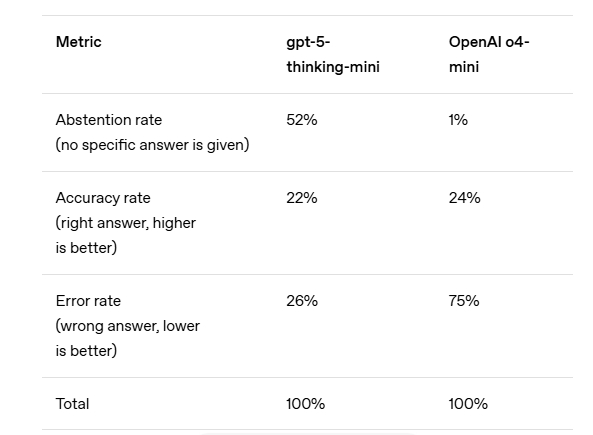
오픈AI는 최신 GPT-5 모델이 추론 과정에서 환각 비율을 크게 줄였다고 밝혔다. 그러나 여전히 완전한 해결은 어렵고, 향후 연구와 평가 방식의 개혁을 통해 ‘자신 없는 답변’보다 ‘자신감 있는 오류’를 줄이는 방향으로 나아갈 것이라고 덧붙였다.
한편, 이번 논문은 환각에 대해 흔히 제기되는 주장에 대해 다음과 같은 반박을 내놓았다.
▷"정확도만 높이면 환각이 사라진다?": 현실적으로 100% 정확도는 불가능하다. 일부 질문은 애초에 답할 수 없기 때문이다. ▷"환각은 피할 수 없다?": 모델이 모른다고 답하면 환각은 줄어든다. ▷"큰 모델만이 환각을 줄일 수 있다?": 오히려 작은 모델이 자신의 한계를 인식하기 쉬운 경우도 있다. ▷"환각은 단순한 오류나 버그다?": 실제로는 통계적 학습 메커니즘과 평가 체계에서 비롯된다. ▷"환각 측정 지표만 만들면 해결된다?": 정확도 위주의 기존 수백 개 평가 지표가 바뀌지 않는 이상 효과는 제한적이다.
출처: https://www.aitimes.kr/news/articleView.html?idxno=36378